

Closed captions are an effective technique to improve accessibility, engagement, and information retention during presentations and live events. This, together with shifting video consumption habits in the realm of video streaming, has recently accelerated the adoption of AI-powered captioning in live events and business meetings.
But when it comes to choosing a provider for your own meeting or event, the question that is most frequently asked is: how accurate are automatic live captions?
The quick answer is that, under ideal conditions, automatic captions in spoken languages can achieve up to 98% accuracy as assessed by Word Error Rate (WER).
And yes, there's a long, slightly more complex answer. In this article, we want to give you an overview of how accuracy is measured, what factors impact accuracy, and how to take accuracy to new heights.
In this article
- How automatic captioning works
- What is considered good captioning quality?
- What factors influence accuracy?
- Measuring the accuracy of automatic captioning
- Understanding Word Error Rate (WER)
- Getting incredibly precise closed captioning for your live events
Before we dive into the numbers, let's take a step back and look at how automatic captions work.
How automatic captioning works
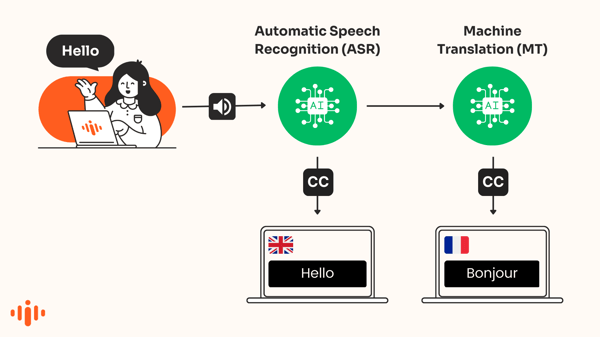
Automatic captions
Automatic captions convert speech into text that shows on screen in real-time in the same language as the speech. ASR - Automated Speech Recognition - is a sort of artificial intelligence used to produce these transcripts of spoken sentences.
The technology, often known as "speech-to-text," is used to automatically recognize words in audio and transcribe the voice into text.
AI-translated captions
AI-powered translation engines automatically translate captions that appear in a different language. This is also known as machine-translated subtitles or machine-translated captions.
Recommended article
Why you should consider adding live captions to your next event
In this article, we're covering automatic captions. If you want to know about the accuracy of AI-translated captions, check this article.
What is considered good captioning quality?
The Federal Communications Commission (FCC) established essential characteristics in 2014 to determine whether captions are "excellent":
- Accuracy -Captions must match spoken words, to the fullest extent possible
- Completeness - Captions run from the beginning to the end of the broadcast, to the fullest extent possible.
- Placement - Captions do not block important visual content and are easy to read.
- Synchronisation - Captions align with the audio track and appear at a readable speed.
Image: AI-translated live captioning during a webinar
What factors influence accuracy?
The selected AI engine
Not all speech-to-text engines produce identical outcomes. Some are better in general, while others are better in certain languages. And even when using the same engine, results can vary greatly depending on accents, noise levels, topics, and so on.
That is why, at Interprefy, we are always benchmarking top engines to determine which generate the most accurate results. As a result, Interprefy can provide users with the best solution for a specific language, taking into account aspects such as latency and cost. Under ideal settings, we have seen consistent accuracy of up to 98% for several languages.
The audio input quality
Quality input is required for automated speech recognition technology to produce quality output. It's simple: the higher the quality and clarity of the audio and voice, the better the outcomes.
- Audio quality - Much like conference interpreting, bad audio input hardware, such as built-in computer microphones can have a negative impact.
- Clear speech & pronunciation - Presenters who speak loud, well-paced, and clearly, will usually be captioned with higher accuracy.
- Background noise - Heavy rumbling, dogs barking, or paper shuffling that is picked up by the microphone can deteriorate the audio input quality heavily.
- Accents - speakers with unusual or strong accents as well as non-native speakers pose problems for many voice recognition systems.
- Overlapping speech - If two people talk over each other, the system will have a very hard time picking up the right speaker correctly.
Recommended article
How accurate are captions in Zoom, Teams, and Interprefy?
How to measure the accuracy of automatic captions
The most common metric to measure ASR accuracy is Word Error Rate (WER), which compares the actual transcript of the speaker with the result of the ASR output.
For example, if 4 out of 100 words are wrong, the accuracy would be 96%.
Understanding Word Error Rate (WER)
WER determines the shortest distance between a transcript text generated by a voice recognition system and a reference transcript that was produced by a human (the ground truth).
WER aligns correctly identified word sequences at the word level before calculating the total number of corrections (substitutions, deletions, and insertions) required to fully align reference and transcript texts. The WER is then calculated as the ratio of the number of adjustments needed to the total number of words in the reference text. A lower WER generally indicates a more accurate voice recognition system.
Word Error Rate Example: 91.7% accuracy
Let's take an example of a word error rate of 8.3% - or 91.7% accuracy and compare the differences between the original transcript of the speech and the captions created by ASR:
| Original transcript: | ASR captions output: |
| For example, I do like only very limited use to be made of the essentials provided I would like to go into one particular point in more detail I fear that I call on individual state parliaments to ratify the convention only after the role of the European court of law has been clarified could have very detrimental effects. | For example, I too would like only very limited use to be made of the exemptions provided I would like to go into one particular point in more detail I fear that the call on individual state parliaments to ratify the convention only after the role of the European court of law has been clarified could have very detrimental effects. |
In this example, the captions missed one word and substituted four words:
- Measures: {'matches': 55, 'deletions': 1, 'insertions': 0, 'substitutions': 4}
- Substitutions: [('too', 'do'), ('use', 'used'), ('exemptions', 'essentials'), ('the', 'i')]
- Deletions: ['would']
The calculation of the Word Error Rate is therefore:
WER = (deletions + substitutions + insertions) / (deletions + substitutions + matches) = (1 + 4 + 0) / (1 + 4 + 55) = 0.083
WER overlooks the nature of errors
Now in the example above, not all errors are equally impactful.
The WER measurement can be deceptive because it does not inform us how relevant/important a certain error is. Simple errors, such as the alternate spelling of the same word (movable/moveable), are not often regarded as errors by the reader, whereas a substitution (exemptions/essentials) might be more impactful.
WER numbers, particularly for high-accuracy speech recognition systems, can be misleading and do not always correspond to human perceptions of correctness. For humans, differences in accuracy levels between 90 and 99% are often difficult to distinguish.
Perceived Word Error Rate
Interprefy has developed a proprietary and language-specific ASR error metric called Perceived WER. This metric only counts errors that affect human understanding of the speech and not all errors. Perceived errors are usually lower than WER, sometimes even as much as 50%. A perceived WER of 5-8% is usually hardly noticeable to the user.
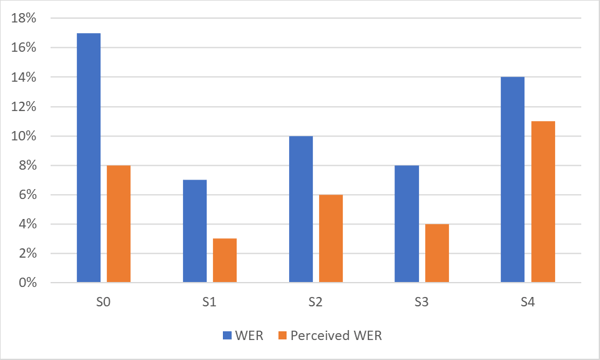
The chart below shows the difference between WER and Perceived WER for a highly accurate ASR system. Note the difference in performance for different data sets (S0-S4) of the same language.
As shown in the graph, the perceived WER by humans is often substantially better than the statistical WER.
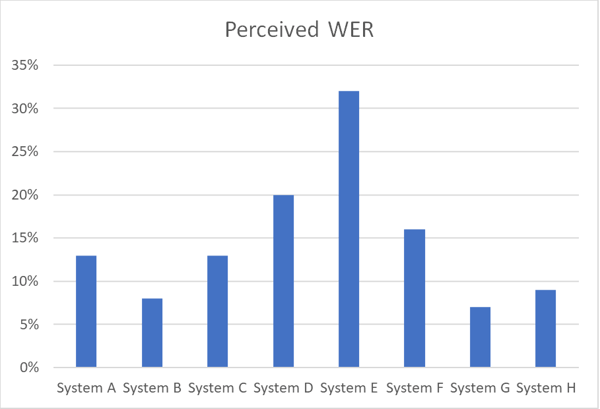
The chart below illustrates differences in accuracy between various ASR systems working on the same speech data set in a certain language using Perceived WER.
Getting incredibly precise closed captioning for your live events
We've seen an accuracy of 97% for our automatic captions thanks to the combination of our unique technical solution and the care we take for our customers. Alexander Davydov, Head of AI Delivery at Interprefy
If you're looking to have highly accurate automatic captions during an event, there are three key things you should consider:
Use a best-in-class solution
Instead of choosing any out-of-the-box engine to cover all languages, go for a provider who utilises the best available engine for each language in your event.
Interested in understanding what the best engine can offer you? Read our article: The Future of Live Captions: How Interprefy AI Powers Accessibility
Optimise the engine
Choose a vendor who can supplement the AI with a bespoke dictionary to guarantee that brand names, odd names, and acronyms are appropriately captured.
Ensure high-quality audio input
If the audio input is bad, the ASR system will not be able to achieve output quality. Make sure, the speech can be captured loud and clearly.


 More download links
More download links



